Exploring new frontiers of Reinforcement Learning with Cedana
Reinforcement Learning (RL) is a conceptually simple yet powerful paradigm: take the current state, evaluate the probabilities of various actions, select the optimal one, and update the base model that generates these predictions.

The field, with deep roots in control theory, is experiencing a renaissance, particularly as we see the standard crop of post-training tools hit a wall. SFT (Supervised Fine-Tuning) is showing diminishing returns - excelling at teaching style and format but having difficulty imparting more reasoning capabilities like Chain of Thought (CoT) and helping models think coherently for longer durations, influencing useful agentic operation.
The chart below from SemiAnalysis shows that models are models getting both cheaper and better - attributed to large frontier labs embracing RL in post-training.

At Cedana, we see a unique opportunity for our live-migration and checkpoint/restore capabilities to unlock new possibilities in the current state-of-the-art of RL.
We’re approaching the problem with an interdisciplinary set of skills. We’ve got extensive experience building large scale ML systems (Neel having built the OG computer vision systems at CSAIL), experience with controls (Niranjan working at the optimization, controls and RL Lab at SUNY Buffalo) and experience with compute infrastructure.
RL as we see it growing in the near future necessitates taking a slightly different approach, as we lay out below.
The State of Reinforcement Learning Today
For a long time, the go-to method for specializing a pre-trained model was Supervised Fine-Tuning (SFT). You show the model thousands of high-quality examples and teach it to mimic them. While effective for learning a specific style (like a customer service chatbot) SFT is inherently limited. It's like giving a student an answer key without teaching them how to solve the problems.
Reinforcement Learning (RL), and specifically techniques like Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO), offer a more robust path forward. Instead of just rewarding a model for matching a 'correct' answer, RL rewards it for the process of finding a good answer. This is crucial for complex tasks like multi-step reasoning and code generation, where many valid paths to a solution exist.
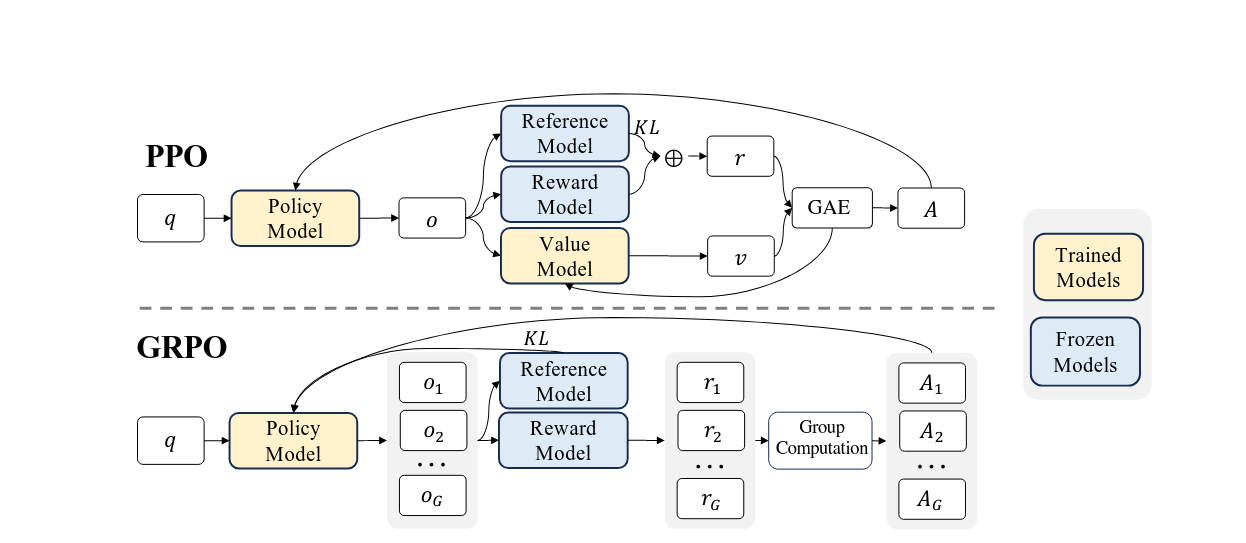
The Re-computation Problem
To understand the challenges in modern RL, let's consider a common task: using an LLM to generate a web application. The LLM agent needs to take a series of actions – writing files, setting up a test environment, adding data to an in-memory database, and so on. Each of these actions mutates the state of the environment and has an associated cost, which can be measured in the cumulative number of LLM API calls required to complete the task.
Now, imagine the agent reaches a "fork in the road" with multiple potential paths forward. To determine the best path, a traditional RL approach would need to explore each one. This often means recreating the entire computational journey from the beginning for each new path, a process that is not only time-consuming but also challenging with non-deterministic actors. An hour of computation might need to be regenerated for every decision point, leading to a massive accumulation of cost.
In RL terminology, each of these forks represents a branch in the policy's trajectory, and exploring it generates a rollout. The high cost comes from the fact that, traditionally, every new rollout must be generated from scratch. If an agent has already completed 100 steps (e.g., API calls, file mutations), exploring a different 101st step requires re-running the first 100. This is computationally prohibitive and makes deep exploration of the decision space at scale nearly impossible.
This is where Cedana comes in.
Snapshotting for Efficient Exploration
Our ability to snapshot the entire state of a computation changes the dynamics of RL. Instead of re-computing from scratch, we can take a snapshot at each "fork in the road." This allows us to explore multiple trajectories in parallel without the massive overhead of regeneration. Past just saving time and resources; we can enable more thorough exploration of the solution space, which is critical for complex reasoning and planning tasks.
This is precisely the bottleneck we address. By creating a complete snapshot of the process state at any step, you can branch off into countless new trajectories without the crippling cost of re-computation. You aren't just saving compute; you're fundamentally enabling more sophisticated and deeper exploration strategies.
The Future of Reinforcement Learning with Cedana
The rise of RL is causing a paradigm shift in how we think about computational cost. While pre-training remains expensive, the big change is the explosion of test-time compute. Advanced models now 'think' before they respond. This can involve generating multiple potential answers and using a learned reward model to pick the best one, or iteratively refining a piece of code until it passes all tests.
This makes inference (or 'test time') a much more dynamic and resource-intensive process than it used to be. Managing this new, spiky, and stateful workload is a major infrastructure challenge—and a key area where Cedana's ability to freeze and restore active processes provides a significant advantage for both developers and the platforms they build on.
At Cedana, we believe the future of RL lies in overcoming the resource-intensive nature of current methods. By providing the tools to efficiently manage and manipulate computational state at scale (tens of thousands of containers and environments), we can accelerate the development of more powerful and capable AI systems. We are excited to see how researchers and developers will leverage Cedana to push the boundaries of what's possible with Reinforcement Learning.
Check out a quick demo of us moving a Stable Baselines 3 RL workload between nodes in Kubernetes:
